 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  BNB
BNB  XRP
XRP  USDC
USDC  Solana
Solana  Dogecoin
Dogecoin  Figure Heloc
Figure Heloc  Cardano
Cardano  Wrapped stETH
Wrapped stETH  WhiteBIT Coin
WhiteBIT Coin  Bitcoin Cash
Bitcoin Cash  Wrapped Bitcoin
Wrapped Bitcoin  Wrapped eETH
Wrapped eETH  USDS
USDS  Binance Bridged USDT (BNB Smart Chain)
Binance Bridged USDT (BNB Smart Chain)  LEO Token
LEO Token  WETH
WETH  Coinbase Wrapped BTC
Coinbase Wrapped BTC  Stellar
Stellar  Ethena USDe
Ethena USDe  Sui
Sui  Zcash
Zcash  Hyperliquid
Hyperliquid  Avalanche
Avalanche  Litecoin
Litecoin  Shiba Inu
Shiba Inu  USDT0
USDT0  Hedera
Hedera  World Liberty Financial
World Liberty Financial  Canton
Canton  sUSDS
sUSDS  Toncoin
Toncoin  Ethena Staked USDe
Ethena Staked USDe  USD1
USD1  Polkadot
Polkadot  MemeCore
MemeCore
Oracles are the indispensable bridge connecting off-chain data (like asset prices) to on-chain smart contracts in Decentralized Finance (DeFi).
However, as DeFi matures, current Oracle solutions struggle to meet the demand for faster, cheaper, and crucially, more accurate data, which we call High Fidelity Data. Past vulnerabilities have underscored the urgent need for a new standard.
Consequently, APRO is engineered to establish this standard. By optimizing for high-fidelity data delivery, APRO promises a new level of safety and efficiency for the next generation of DeFi applications.
What Is APRO?
APRO is not merely a data provider. Instead, it is a decentralized oracle architecture designed to tackle the oracle trilemma: how to simultaneously achieve speed, low cost, and absolute fidelity (accuracy).
If the first generation of Oracles focused on creating basic data bridges and the second generation centered on increasing decentralization, APRO, as the third generation, is focused on data quality at the level of high fidelity.
This is APRO’s core value. High-fidelity data encompasses three crucial elements:
- Granularity: Extremely high update frequency (e.g., every second instead of every minute).
- Timeliness: Near-zero latency, ensuring data is transmitted instantly after aggregation.
- Manipulation Resistance: Data is aggregated from a large, verified number of sources, eliminating the possibility of price attacks originating from a single exchange.
Ultimately, by providing data with unprecedented accuracy and speed, APRO unlocks the ability to create novel DeFi products that were previously too risky or technologically unfeasible (e.g., short term derivative contracts).

What Is APRO? Source: APRO
Learn more: NFTevening Top Pick: Everything about OKX Exchange
APRO’s Core Technology and Innovation
APRO’s architecture is a sophisticated layered system designed to process complex, unstructured data and ensure data integrity during transmission:
The Layered System Architecture
APRO separates the tasks of data acquisition/processing and consensus/auditing to maximize performance and security.
Layer 1: AI Ingestion (Data Acquisition and Processing)
This first layer (L1) serves as the acquisition and raw data transformation layer.
-
Artifact Acquisition: L1 Nodes acquire raw data (artifacts) such as PDF documents, audio recordings, or cryptographically signed web pages (TLS fingerprints) via secure crawlers.
-
Multi-modal AI Pipeline: The Node runs a complex AI processing chain: L1 uses OCR/ASR to convert unstructured data and NLP/LLMs to structure the text into schema compliant fields.
-
PoR Report Generation: The output is a signed PoR Report, containing evidence hashes, structured payloads, and per field confidence levels, which is ready for submission to L2.
Layer 2: Audit & Consensus (Auditing and Finalization)
Meanwhile, Layer 2 (L2) is the validation and dispute resolution layer, which guarantees the integrity of L1 data.
- Watchdogs and Independent Auditing: Watchdog Nodes continuously sample submitted reports and independently recompute them using different models or parameters.
- Dispute Resolution and Proportional Slashing: The mechanism allows any staked participant to dispute a data field. If the dispute succeeds, the offending reporting Node is slashed proportional to the impact of the error, creating a robust, self correcting economic system.
Dual Data Transport Model and Data Integrity Mechanisms
APRO combines its Layered Architecture with a dual transport model to optimize performance on EVM chains.
- Data Push: Delivers finalized data from Layer 2. Following PBFT consensus and dispute resolution, Nodes execute a transaction to push the final data onto the smart contract. Suitable for dApps requiring foundational on chain data availability.
- Data Pull: Exploits the ultra high frequency performance of Layer 1. L1 allows Nodes to sign high accuracy price and PoR reports off chain at extremely high frequencies. Data Pull is the user-initiated process of fetching and verifying that signed proof on chain, effectively decoupling gas cost from data frequency.
Core Price Discovery and Anti-Manipulation
Data quality is ensured through robust algorithms and consensus mechanisms:
-
TVWAP Pricing: APRO uses the TVWAP (Time Volume Weighted Average Price) to calculate prices weighted by both volume and time, thereby actively mitigating small-scale price manipulation attempts.
-
PBFT Consensus and Reputation System: Furthermore, the fast PBFT consensus mechanism is combined with the Validator Reputation Scoring System to ensure Nodes are subject to economic penalties (slashing) if they provide stale or malicious data. Consequently, this approach maintains a strong economic barrier to entry for dishonest actors.
APRO’s Core Technology and Innovation – Source: APRO
Non Standard Oracle Capabilities
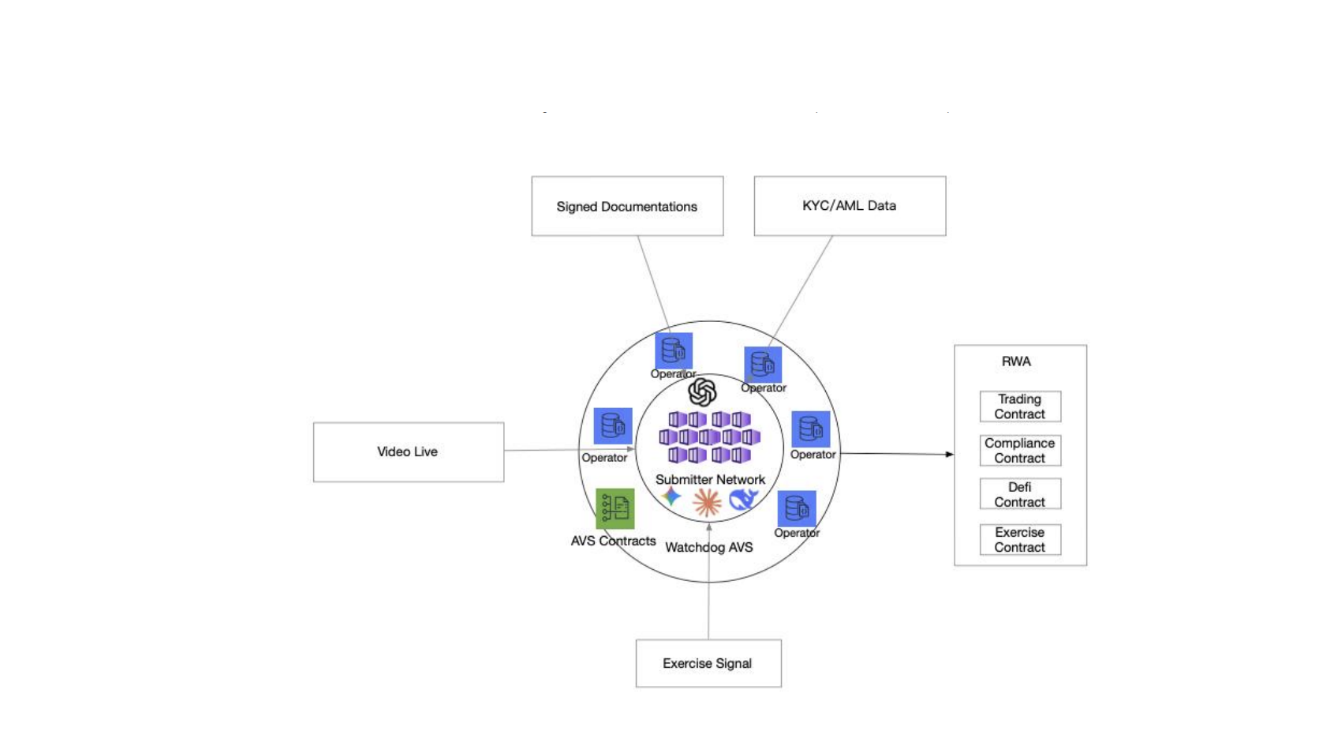
APRO’s analytical capabilities extend far beyond conventional crypto Price Feeds, focusing on complex RWA/PoR verticals:
Proof of Reserve (PoR) and Automated Auditing
APRO elevates PoR to an automated auditing function:
- Multi modal Source Processing: The L1 AI Pipeline analyzes complex evidence like bank letters or regulatory filings via OCR/LLM.
-
Legal Consistency: Consequently, L2 performs Reconciliation Rules to ensure totals across documents match (e.g., verifying asset liability summaries), thereby drastically reducing human error and manipulation risks in reserve reporting.
RWA and Niche Scenarios
APRO provides a detailed Oracle Capability Matrix for complex RWA fields, transforming the Oracle into a sophisticated verification tool:
- Pre IPO Shares: L2 performs cap table reconciliation, ensuring share counts align with the total authorized shares. Outputs include last round valuation and a provenance index.
- Legal/Agreements: The Oracle analyzes contracts, extracting obligations and enforceability signals. L2 verifies digital signatures and cross references public court dockets, allowing smart contracts to enforce complex legal terms.
- Real Estate: APRO processes documents like land registry PDFs and appraisal reports, extracting title/encumbrance facts. L2 can mirror registry snapshots for verification, addressing a core problem of real estate tokenization.
The convergence of the Layered Architecture and the Multi modal AI Pipeline enables APRO to not only deliver faster price data but also to ensure contextual accuracy and institutional grade auditability for the most complex assets.
APRO Tokenomics
APRO’s native utility token is $AT, with a Maximum Supply of 1,000,000,000 tokens.
The $AT token functions as the economic core, driving network security through staking and facilitating data service payments, ultimately promoting platform sustainability.
Learn more: APRO (AT) Will Be Listed on Binance HODLer Airdrops!
Token Allocation
The $AT token allocation structure is designed to balance ecosystem development, security, and initial capital distribution:

Token Allocation – Source: APRO
- Ecosystem: 25%
- Staking: 20%
- Investor: 20%
- Public Distribution: 15%
- Team: 10%
- Foundation: 5%
- Liquidity: 3%
- Operation Event: 2%
The combined allocation of 45% to Ecosystem and Staking underscores APRO’s highest priority: enhancing network security and building a robust community of Validator Nodes, which is a prerequisite for a successful next generation Oracle platform.
FAQ
What is APRO?
APRO is a third generation Decentralized Oracle Architecture designed to deliver High Fidelity Data (extreme accuracy and timeliness). It solves the Oracle Trilemma. Its core innovation is a Layered System. This system uses an AI Pipeline (OCR/LLM) in Layer 1 to transform complex, unstructured data into auditable information. Crucially, APRO specializes in non standard verticals like RWA and Proof of Reserve (PoR).
What is the primary difference between APRO and established Oracle platforms?
The fundamental difference lies in the Layered Architecture and Data Pull. APRO focuses on High Fidelity Data via the L1 AI Pipeline and uses Data Pull to deliver ultra high frequency data cost effectively on EVM chains.
How does APRO ensure RWA data reliability?
RWA data is processed by the Multi modal AI Pipeline in L1. RWA data is processed by the Multi modal AI Pipeline in L1. Nevertheless, it must pass L2’s rigorous auditing process. Specifically, this process includes outlier filtering and achieving PBFT consensus from the diverse Node network. Furthermore, L2 also performs Reconciliation Rules for complex financial documents.
What mechanisms protect APRO from price manipulation attacks?
APRO uses a combination of defenses: TVWAP and outlier rejection algorithms for technical data cleaning, along with the proportional slashing system based on reputation scores to enforce economic honesty.
How does Data Pull remain cost efficient despite frequent updates?
Data Pull shifts the continuous update burden from the Nodes to the end-user. Nodes sign fresh price proofs off chain (gas free). The user only pays a single gas fee for their transaction, when they pull the signed proof onto the smart contract for verification.


